OCR
An estimated one to two million cuneiform tablets, discovered globally and housed in various collections, remain largely unexplored. Only around 15-20% of these tablets have been deciphered, translated, and studied, with a significant portion remaining uncatalogued due to scattering and a shortage of cuneiform specialists. The use of Optical Character Recognition (OCR) is proposed to address this challenge by automatically providing a preliminary decryption of the tablets, facilitating tentative identification of their genre and dating through machine learning approaches. This automatic process will expedite the complete transliteration and translation of tablets, allowing specialists to efficiently process more relevant data for historical and linguistic research.
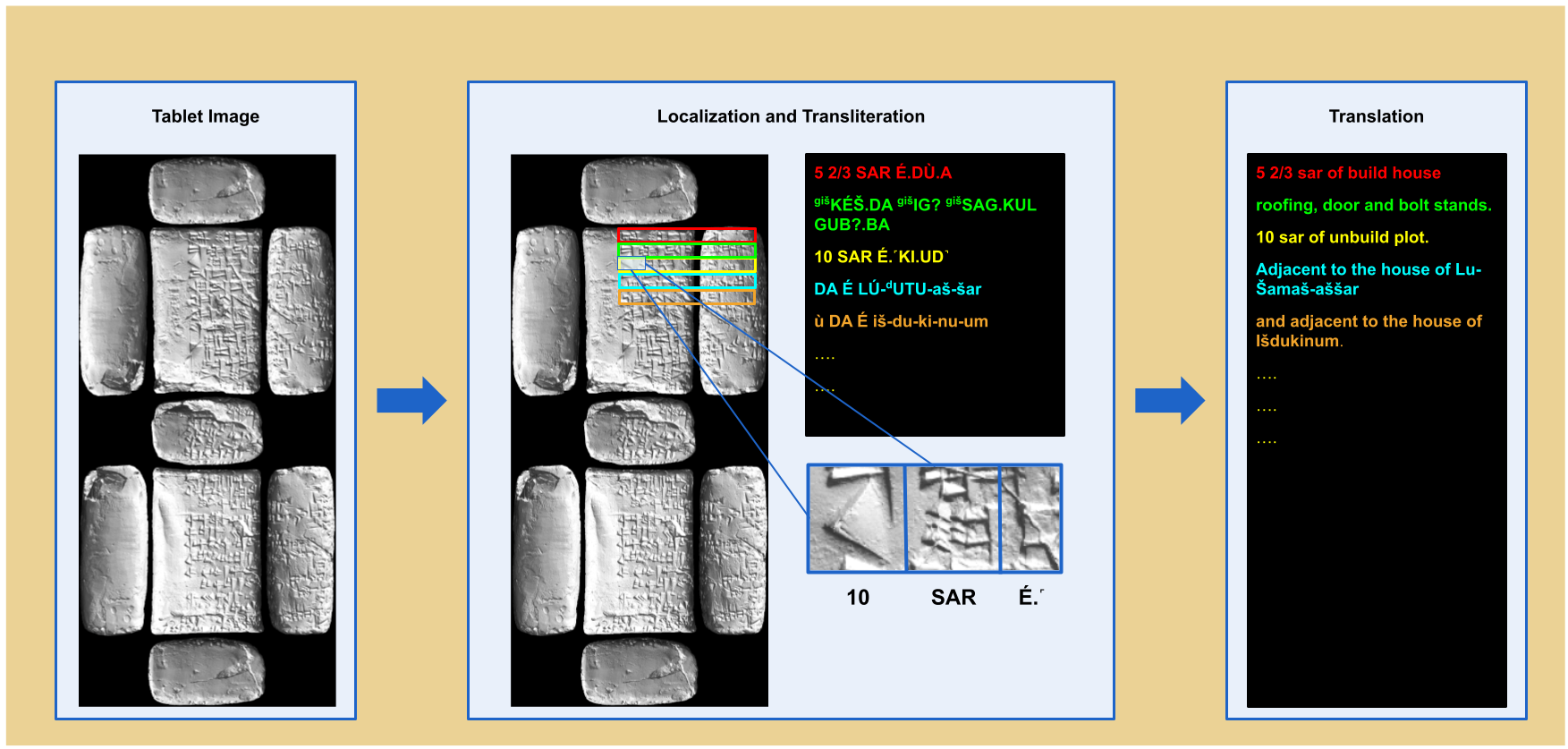
Optical Character Recognition of Cuneiform Script is still in its early stages, and this sub-corpus will be enhanced with cuneiform tablets from other Old Babylonian collections globally. After transcription and translation, a comprehensive interpretation and analysis will be conducted using prosopographical research methods. Entities such as Personal Names, Institutions (e.g., Temples, Palaces), Dates, and Geographic Entities will be annotated using tools like Recogito. Geo-spatial data, annotated at various levels of granularity, will provide insights into cities (e.g., Sippar, Larsa, Nippur) or more detailed locations (e.g., Urban Gazetteers).
2D+ Images
2d plus tablet images are imaged using a special light dome, so that there are 12 visualizations of the tablet:
- 8 tablet images with 8 different lighting angles as shown in image below.

- 1 top and 3 generated visualizations (2 sketch and 1 normal) as shown in image below
Experiment: Effect of Light Source on Sign Localization
Objective:
This experiment investigates how different lighting conditions affect the accuracy of cuneiform sign detection and localization. By training models on individual visualizations under varying lighting positions, we aim to determine which setup provides the best visibility and maximizes detection accuracy. The findings will offer valuable insights into the optimal imaging conditions required to enhance the performance of sign detection algorithms.
Setup:
Cuneiform tablet sides were divided into training, validation, and testing sets in a 70:20:10 ratio. For each visualization, a YOLOv8l-detect model was trained for 125 epochs with a batch size of 4, incorporating mosaic augmentation to enhance variability and robustness.
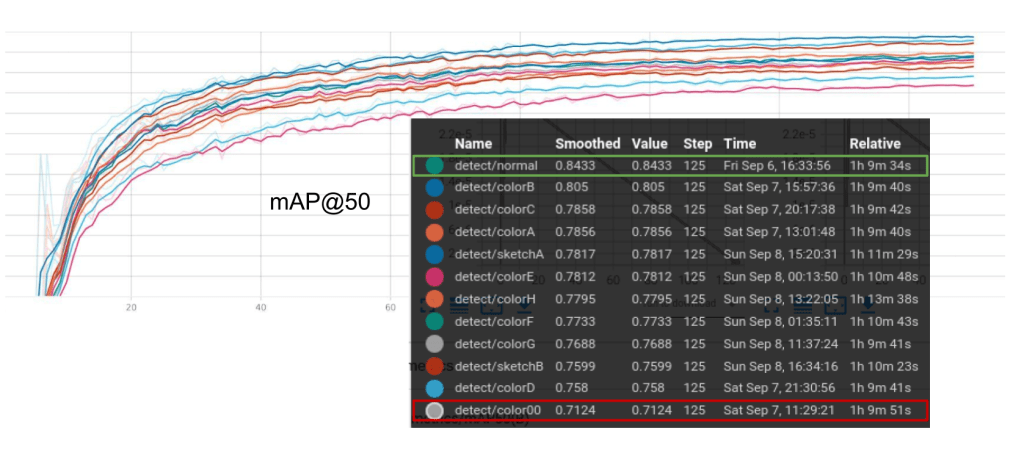
Result:
A performance gap of approximately 15% in mAP scores is observed between the best- and worst-performing visualizations. Notably, the Color00 visualization mimics the light source orientation of popular flatbed scans, which have been predominantly used for digitizing cuneiform tablets.
